Info
tenx_
10x Genomics (2023)
341.68 MiB
23-09-2024
9079 cells × 18026 genes
tenx_
10x Genomics (2023)
341.68 MiB
23-09-2024
9079 cells × 18026 genes
CREATED
23-09-2024
DIMENSIONS
9079 × 18026
The tissue was sectioned as described in the Visium CytAssist Spatial Gene Expression for FFPE Tissue Preparation Guide (CG000518). Tissue section of 5 µm was placed on a standard glass slide, then stained following the Deparaffinization, H&E Staining, Imaging & Decrosslinking Demonstrated Protocol (CG000520). The glass slide with tissue section was processed via Visium CytAssist instrument to transfer analytes to a Visium CytAssist Spatial Gene Expression Slide v2, with 11 mm capture areas following the Visium CytAssist Spatial Gene Expression Reagent Kits User Guide (CG000495).
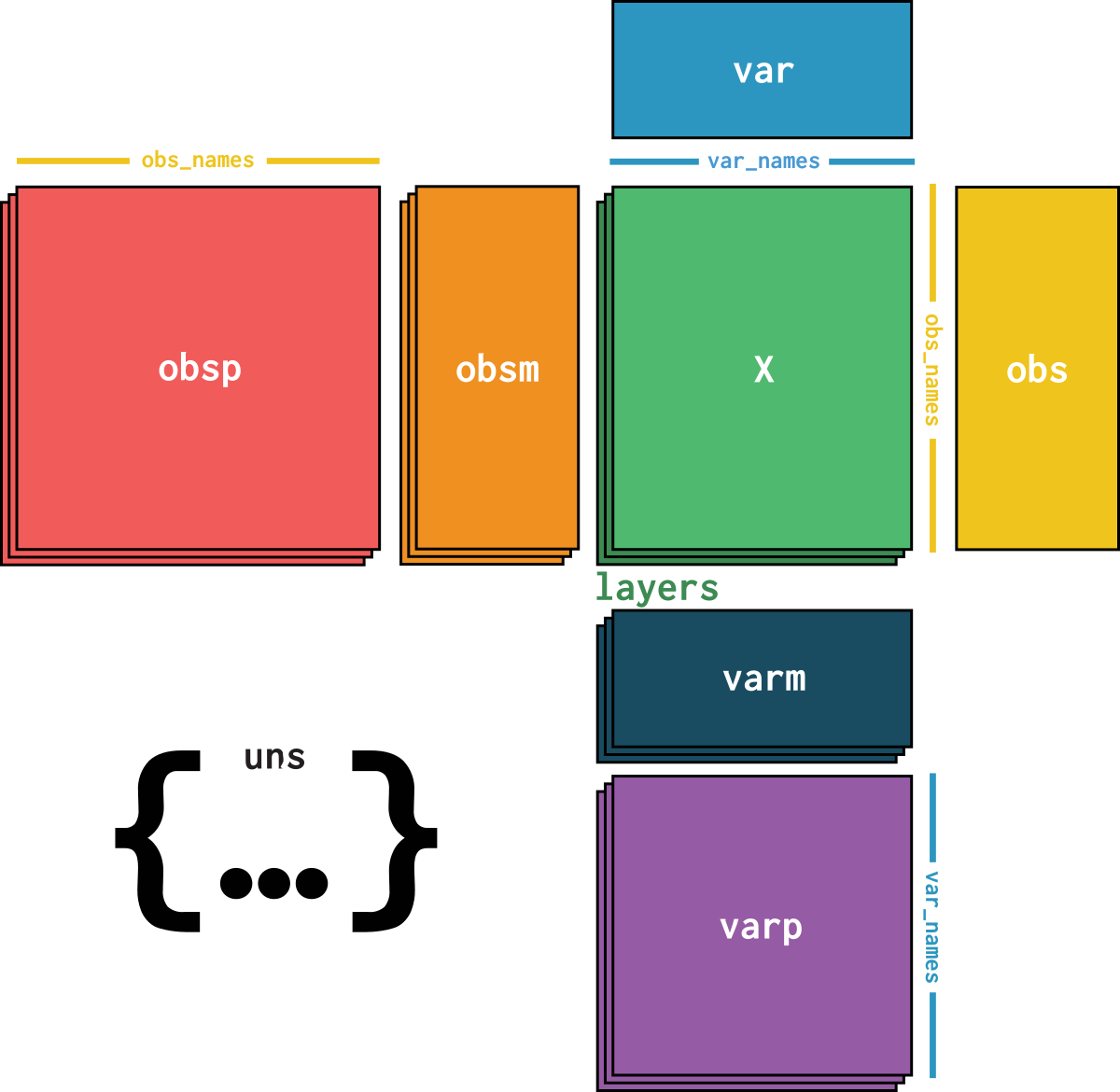
dataset is an AnnData object with n_obs × n_vars = 9079 × 18026 with slots:
feature_id, feature_namecountsdataset_description, dataset_id, dataset_name, dataset_organism, dataset_reference, dataset_summary, dataset_url| Name | Description | Type | Data type | Size |
|---|---|---|---|---|
| var | ||||
feature_
|
Unique identifier for the feature, usually a ENSEMBL gene id. |
vector
|
object
|
18026 |
feature_
|
A human-readable name for the feature, usually a gene symbol. |
vector
|
object
|
18026 |
| layers | ||||
counts
|
Raw counts |
sparsematrix
|
float32
|
9079 × 18026 |
| uns | ||||
dataset_
|
Long description of the dataset. |
atomic
|
str
|
1 |
dataset_
|
A unique identifier for the dataset. This is different from the obs.dataset_id field, which is the identifier for the dataset from which the cell data is derived.
|
atomic
|
str
|
1 |
dataset_
|
A human-readable name for the dataset. |
atomic
|
str
|
1 |
dataset_
|
The organism of the sample in the dataset. |
atomic
|
str
|
1 |
dataset_
|
Bibtex reference of the paper in which the dataset was published. |
atomic
|
str
|
1 |
dataset_
|
Short description of the dataset. |
atomic
|
str
|
1 |
dataset_
|
Link to the original source of the dataset. |
atomic
|
str
|
1 |