Info
zenodo_
Stickels et al. (2020)
62.1 MiB
23-09-2024
21941 cells × 6420 genes
zenodo_
Stickels et al. (2020)
62.1 MiB
23-09-2024
21941 cells × 6420 genes
DATASET ID
zenodo_spatial/slideseqv2/mouse_somatosensory_cortex_puck
REFERENCE
Stickels et al. (2020)
SIZE
62.1 MiB
CREATED
23-09-2024
DIMENSIONS
21941 × 6420
Gene expression library of mouse somatosensory cortex puck profiled using Slide-seq V2.
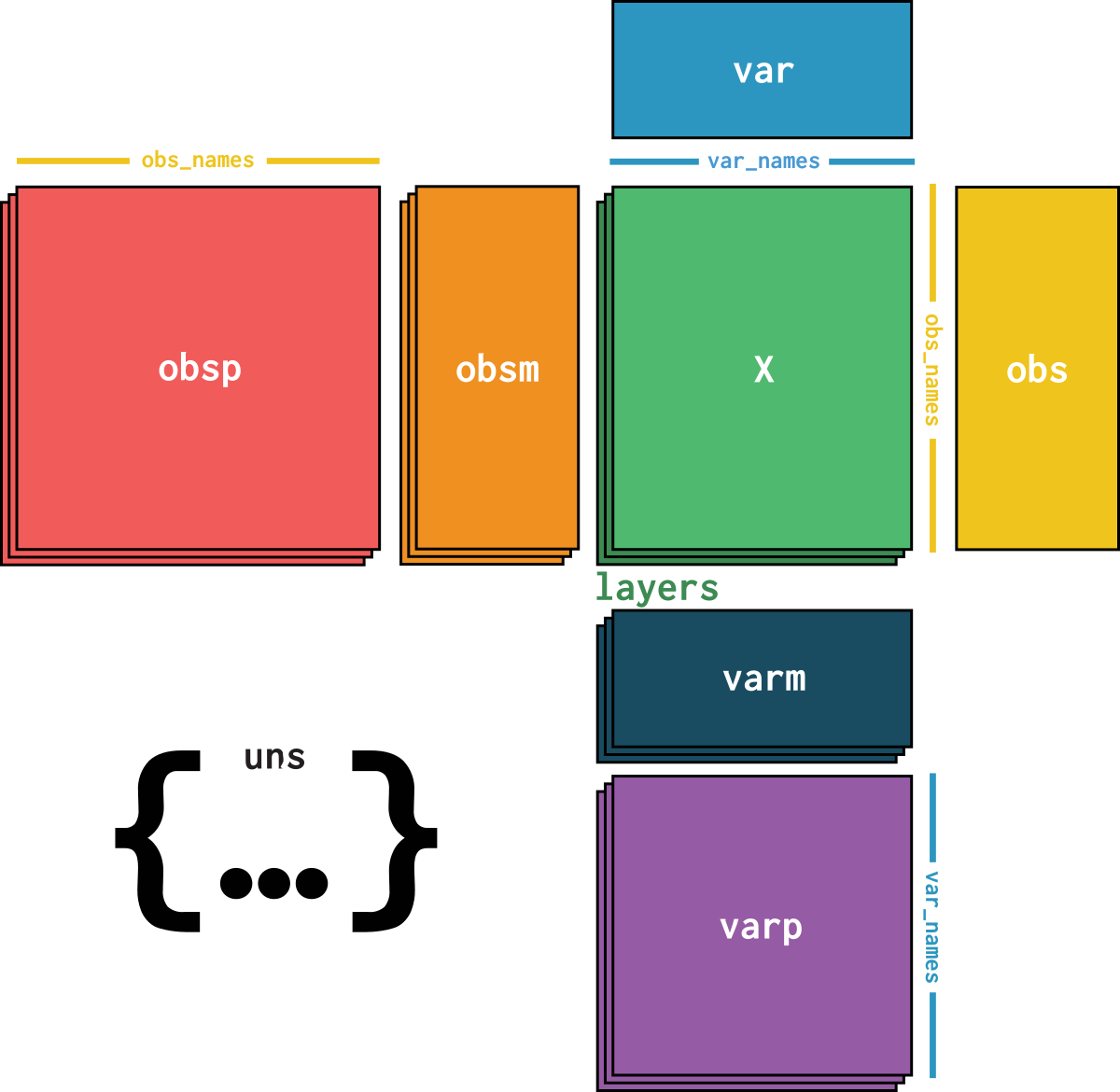
dataset is an AnnData object with n_obs × n_vars = 21941 × 6420 with slots:
feature_namecountsdataset_description, dataset_id, dataset_name, dataset_organism, dataset_reference, dataset_summary, dataset_url| Name | Description | Type | Data type | Size |
|---|---|---|---|---|
| var | ||||
feature_
|
A human-readable name for the feature, usually a gene symbol. |
vector
|
object
|
6420 |
| layers | ||||
counts
|
Raw counts |
sparsematrix
|
int64
|
21941 × 6420 |
| uns | ||||
dataset_
|
Long description of the dataset. |
atomic
|
str
|
1 |
dataset_
|
A unique identifier for the dataset. This is different from the obs.dataset_id field, which is the identifier for the dataset from which the cell data is derived.
|
atomic
|
str
|
1 |
dataset_
|
A human-readable name for the dataset. |
atomic
|
str
|
1 |
dataset_
|
The organism of the sample in the dataset. |
atomic
|
str
|
1 |
dataset_
|
Bibtex reference of the paper in which the dataset was published. |
atomic
|
str
|
1 |
dataset_
|
Short description of the dataset. |
atomic
|
str
|
1 |
dataset_
|
Link to the original source of the dataset. |
atomic
|
str
|
1 |